Does a single direction mediate refusal? A small reproduction
interpretability
safety
steering
transformers
A reproduction of Arditi et al. 2024 on a 1.5B chat model: ablating one difference-of-means direction lowered held-out harmful refusal where a norm-matched random direction did not, and adding it raised harmless refusal. A first model could not be tested at all, which is part of what the exercise taught me.
The question
Refusal of harmful instructions is a behaviour that safety fine-tuning installs in a chat model, and it is not obvious how that behaviour is organised internally. It could be distributed across many heads and layers, or it could be concentrated in a small part of the representation. Arditi et al. 2024 (“Refusal in Language Models Is Mediated by a Single Direction”, NeurIPS 2024) report the concentrated case: across thirteen open chat models up to 72B, they find a single residual-stream direction whose removal suppresses refusal of harmful instructions and whose addition elicits refusal on harmless ones.
I wanted to see what that procedure does on a model small enough to run on a single 8 GB GPU, partly to learn the method by reproducing it and partly to see how cleanly the result holds at a scale far below the original sweep. This post reports what I measured, what one of the two models I tried could not tell me, and how far I think the measurements license me to go. I am newer to interpretability than to the signal-processing it borrows from, so I have tried to keep the claims close to the evidence and to flag where I am inferring rather than measuring.
Prefer to poke at it first? Jump to the interactive simulation further down, or open it on the playground.
The procedure
The construction is a difference of means, the same one the paper uses. For a given layer, I take the model’s residual-stream activation at the final instruction token, average it over a set of harmful instructions (AdvBench goals) and over a set of harmless instructions (Alpaca), and define the candidate refusal direction as the difference of those two averages. Directions are fit on a train split; all refusal rates are measured on held-out instructions, so a direction is never scored on the prompts that defined it.
Two interventions probe whether that direction is doing causal work:
- Ablation (suppression test). Project the direction out of the residual stream at every layer while the model generates on held-out harmful prompts, and measure how often it still refuses.
- Addition (induction test). Add the direction back, at a single chosen layer, while the model generates on held-out harmless prompts, and measure how often it now refuses.
Refusal is scored with the coarse substring classifier the original uses: a completion counts as a refusal if it opens with a refusal phrase (“I cannot”, “I’m sorry”, and similar). The classifier is blunt, so I treated only large shifts as informative and reported the rates rather than any single summary number.
The control the result depends on
The measurement I trust least on its own is the ablation. A reduction in refusal after removing the direction is only interpretable against a null, because perturbing the residual stream is not a neutral act. Korznikov et al. 2025 (“Rogue Scalpel”) report that even a random vector, if it is large enough, shifts a model’s behaviour. So a drop in refusal after ablation is, by itself, consistent with two explanations: that the specific direction mattered, or that any perturbation of comparable size would have moved the behaviour.
To separate those, every arm is run a second time with a norm-matched random direction: a random vector scaled to the same magnitude as the fitted direction. I fixed the decision rule in code before running anything on a model, so the threshold was not chosen after seeing the numbers. The rule asks the ablation to lower harmful refusal by at least 0.5 relative to baseline and by at least 0.25 relative to the random control, and the addition to raise harmless refusal by the same two margins. The margins are deliberately wide because the classifier is coarse; the intent was to make a small wobble fail to register as an effect.
A model that could not be tested
The first model I tried was Gemma 3 1B, chosen for continuity with earlier work. It did not reach the point where the direction could be judged. Its baseline refusal on held-out AdvBench goals was about 0.40 across two seeds, below the 0.5 floor I had set in advance for a measurable suppression effect. The pre-registered rule returned NO-BASELINE-REFUSAL: the model does not refuse often enough at baseline for a reduction to be meaningful.
I am inclined to read this as a property of the instrument rather than a result about refusal directions, and it echoes a lesson from an earlier post here, where a probe that scored perfectly at the embedding layer was reading the input rather than a computation. A near-floor outcome can mean the model is the wrong place to look for the effect, not that the effect is absent. The careful response seemed to be to record the null and move to a model that exhibits the behaviour, rather than to relax the threshold until something registered. I cannot say from this whether a single refusal direction exists in Gemma 3 1B; I can only say this procedure could not test for one there.
What the second model showed
Qwen2.5-1.5B-Instruct refused every held-out harmful prompt at baseline (rate 1.00), which makes the suppression test meaningful. Fitting the direction across layers and selecting the one with the largest validation swing chose layer 14. The held-out measurements were:
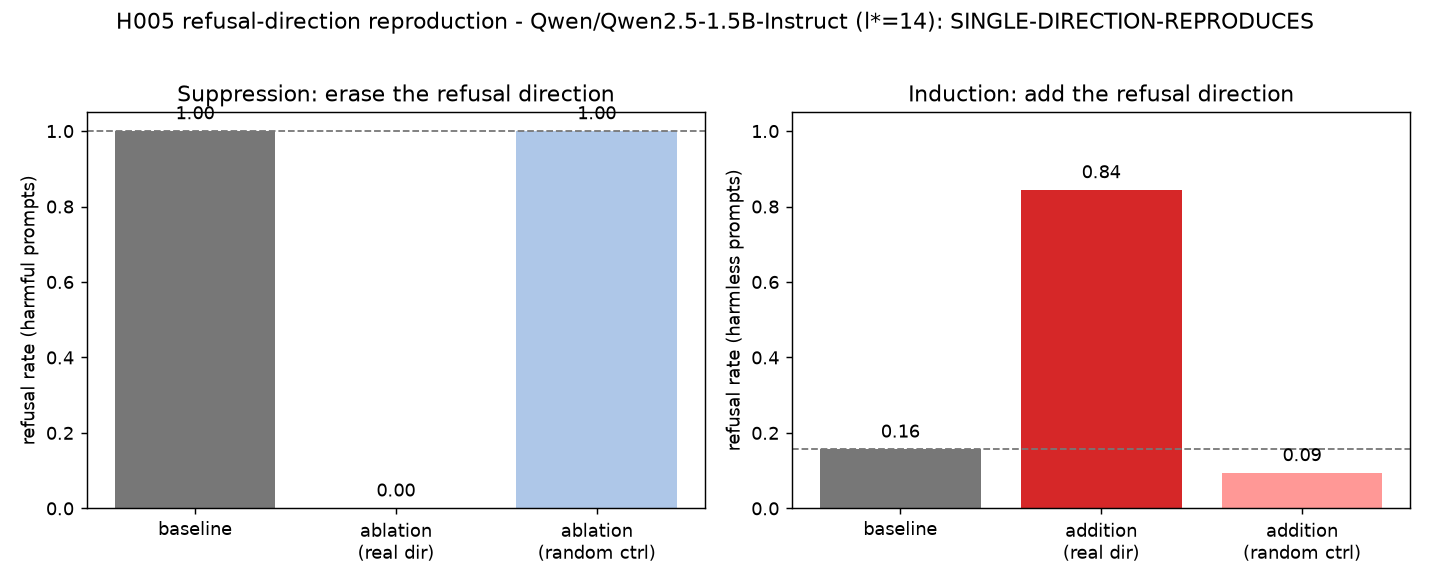
- Suppression. Ablating the fitted direction lowered held-out harmful refusal from 1.00 to 0.00. Ablating the norm-matched random direction left it at 1.00.
- Induction. Adding the fitted direction raised held-out harmless refusal from 0.16 to 0.84. Adding the random direction left it near baseline, at 0.09.
A second seed, which re-samples the instructions and re-fits the direction, selected the same layer and produced the same pattern (ablation 0.12 with the control at 1.00; addition 0.94 with the control at 0.19). So the gap between the fitted direction and the norm-matched control is not an artefact of one particular split.
These are measured interventions, not correlations, and the control rules out the “any large perturbation would do” explanation for this model. What I think they support is narrow: on Qwen2.5-1.5B-Instruct, one difference-of-means direction is a sufficient handle to move the refuse-or-comply behaviour in both directions. That is the claim I am comfortable making from the numbers.
What I do not think this shows
The result is easy to over-read, and two recent papers mark the boundaries I think it respects.
Sufficiency is not representation. Showing that one direction is enough to flip the behaviour does not show that refusal is stored along a single axis. Joad et al. 2026 report that refusal decomposes into several geometrically distinct directions, while steering along any of them produces a similar refusal trade-off; on their reading the directions act as a shared one-dimensional control, and the main thing the choice of direction changes is how the model refuses rather than whether it does. A clean positive here appears consistent with that picture, so I would not upgrade “a sufficient intervention” to “refusal is one direction.”
One direction was not the whole question. The first run fit one direction by construction, so it could not tell me whether a second direction would add anything. I ran that follow-up after publishing the post, on the same Qwen model and the same harmful-refusal suppression arm. The one-direction intervention was made milder by ablating only the selected layer (layer 14), which left real headroom: harmful refusal fell from 1.00 to 0.50, not to zero. But adding a cheap SOM/k-means-proxy second direction did not reduce it further: {d1,d2} also left refusal at 0.50, while the random orthogonal control left it at 0.44. A second seed agreed on the verdict.
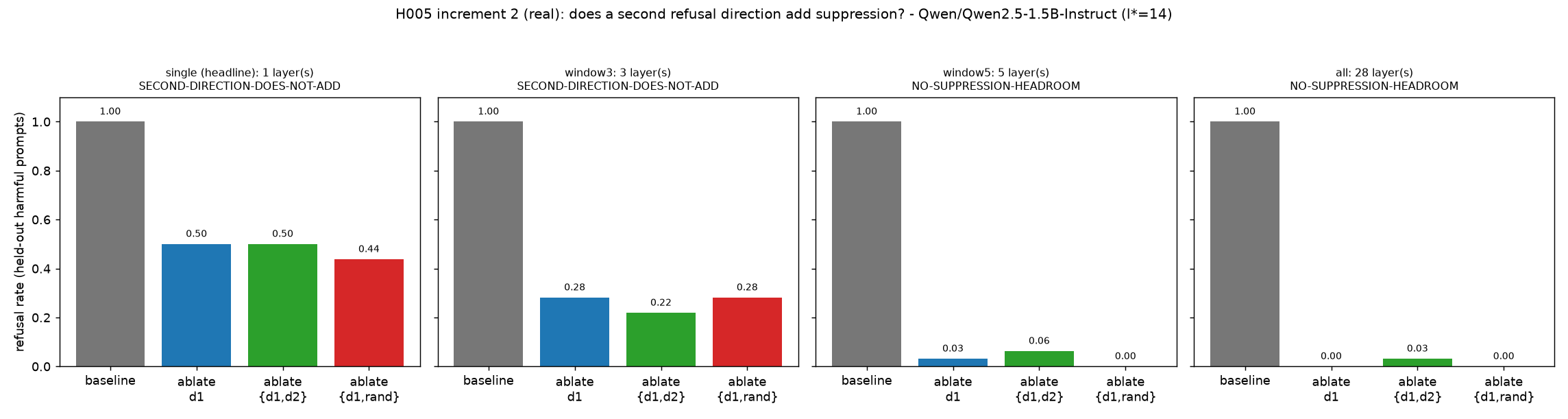
H005 second-direction follow-up on Qwen2.5-1.5B-Instruct. The headline single-layer ablation at layer 14 leaves harmful refusal at 0.50 after d1 alone, so there is room for a second direction to help. The cheap SOM/k-means-proxy second direction leaves refusal at 0.50 as well, and does not beat the random orthogonal control. Wider coverage saturates the test, reproducing the all-layer floor from the original run. I read this as a bounded negative, not as “refusal is one-dimensional.” It says the cheap second direction did not add binary harmful-refusal suppression here. Maskey et al. 2026 locate the higher-dimensional part in over-refusal, where safe prompts resemble harmful ones. That is a different arm from the suppression test above.
I have since run that over-refusal addition arm too, using benign-but-scary FalseReject prompts. The global over-refusal direction was distinct from d1 and beat the random orthogonal control, but it missed the pre-set add-margin past d1 alone: on the primary seed at the headline dose, +d1 raised safe-target refusal to 0.60, +{d1,d_over} to 0.81, and +{d1,control} to 0.56. A second seed gave the same verdict. I read that as another bounded negative, this time for a global single-layer d_over, not as closure. The next useful probe is more specific: fit the over-refusal direction by task category rather than averaging all scary-looking prompts together.
The readout is coarse. A substring classifier only sees whether a completion opens with a refusal phrase. I trust the direction of a large, control-beating shift; I would not read anything into a small one, and a more careful refusal judgement could change the rates.
This is one model at one scale. The numbers are a reproduction on Qwen2.5-1.5B-Instruct, not a restatement of the 72B-scale claim. The Gemma outcome is a reminder that even baseline refusal does not transfer across nearby small models, so I would be cautious about generalising the geometry from a single case.
Why the fragility is the interesting part
If the measurements are read at face value, the part worth dwelling on is how little it took to move the behaviour. A property installed by safety fine-tuning was, on this model, shifted in both directions by a vector built from a difference of means and applied with a projection or an addition. I do not want to overstate what that implies about safety in general from one 1.5B model, but it is at least suggestive that a behaviour can present as robust in text while resting on a low-dimensional and editable feature, and that seems worth understanding whether the goal is to defend the behaviour or to interpret it.
See it move
The numbers above are static; the mechanism is not. Below are two interactive views of it. Neither runs a real language model in your browser, and I want to be exact about what each one is, because the gap between them is part of the point.
The first is the measured evidence from this post, made explorable: the held-out refusal rates I actually recorded on Qwen2.5-1.5B-Instruct and Gemma 3 1B, nothing generated live. The second is a toy whose refusal is, by construction, one known direction, the same synthetic planted-direction model the companion code ships. The toy is where you can turn the knobs, because it is honest to turn them: there is no real weight or harmful prompt anywhere in it, only synthetic activations and canned phrases. What carries over from the toy to the real model is the shape of the result, not any specific number.
What is and isn’t real here
Real 1.5B inference with live residual-stream edits will not run client-side, and nobody should download multi-gigabyte weights to read a blog post. So the measured view replays committed metrics (traceable to the evidence ledger), and the toy view computes a 64-dimensional synthetic model live in your browser. The toy keeps the same discipline as the real pipeline: it shows refusal rates and direction geometry, and it never displays a real harmful completion, only its own canned strings.
The measured result
This is the data behind the figure earlier in the post. Pick a model and an arm. The bars are held-out refusal rates; the fitted direction is the difference-of-means refusal direction, the random control is a norm-matched random vector. A real single-direction effect is the fitted bar clearing the control bar by the pre-registered margin in both arms.
The toy you can steer
Now the synthetic model. Its refusal is genuinely one-dimensional: it refuses a prompt exactly when that prompt’s activation projects past a threshold \(\theta\) onto one planted axis. Difference-of-means recovers that axis without being told it; the controls below let you watch the intervention act on the decision variable directly.
The histogram is the held-out test cloud projected onto the model’s true refusal axis, before (faint) and after (solid) the intervention. The dashed line is \(\theta\): everything to its right refuses. Switch direction to the random control and the cloud stops moving, which is the whole reason the control exists.
The toy makes a clean positive look easy. The measured view is the reminder that it is not: the same procedure returned NO-BASELINE-REFUSAL on Gemma, and the follow-up arms (the second-direction and over-refusal addenda below) are bounded negatives. The interactive is here to build intuition for the mechanism, not to upgrade a 1.5B reproduction into a claim about refusal in general.
I have kept the companion code scoped to the interpretability question rather than the manipulation. It runs on a synthetic planted-direction model by default, with no real weights and no harmful content; its optional real mode only discovers the direction and reports where harmful and harmless instructions separate, and it writes refusal rates and the figure above, never generated text.
What the exercise taught me
- The control is most of the experiment. “Refusal fell after I ablated the direction” was not interpretable until the norm-matched random direction failed to reproduce it. The comparison, more than the raw drop, is what let me attribute the effect to the direction on this model.
- A near-floor result can be the instrument talking. The NO-BASELINE-REFUSAL outcome on Gemma 3 1B was more useful as a check than as a disappointment: it kept me from scoring an intervention on a model that had little refusal to remove.
- Sufficiency and representation are different claims. Distinguishing “one direction is enough to move the behaviour” from “refusal lives on one axis” was the part I found easiest to blur and most important to keep separate, and the recent literature is what helped me see where the line sits.
Companion code is a runnable reproduction on a synthetic planted-direction model (no GPU, no harmful content), with an optional --real mode that discovers the difference-of-means direction on a chat model’s activations: see the h005_refusal_direction sample. I am still early in this area, so if you work on steering or refusal and see somewhere I have over-read the evidence, I would value the correction.