From consuming a pretrained model to training my own
An organisation-wide hackathon, a partner, and a ceiling I didn’t expect
My teammate Sharon and I entered an organisation-wide hackathon with over 11,000 project submissions. We set out to build a sign-language Copilot. Sharon owned the agent integration and tooling: Microsoft Agent Framework, the WorkIQ MCP for M365, the RAG-augmented translator that turns recognised gloss into clean English, and the Qt UI’s higher-level event handling. I owned the part you don’t see: the modelling and inference engine that turns webcam frames into something the agent can actually act on. The project went on to win first place in the challenge.
The reason this was a real project and not a clever demo: as far as we could find, there is no published methodology for using sign language as an interface to an AI agent, and there are no foundational models designed for continuous or conversational signing. Production sign-language systems are isolated-gloss recognisers; the research literature is dominated by isolated-sign benchmarks. Conversational signing, the way a deaf user would actually dictate to a Copilot, is an open problem. Our project was a novel attempt to train a continuous-signing model from scratch, including a novel processing workflow for the multi-angle video clips the dataset ships in.
We shipped a working demo by Friday night, built around a strong pretrained isolated-gloss classifier (the Kaggle 1st-place ASL TFLite model). It could recognise “hello”, “thank you”, “schedule” with high confidence. By Sunday afternoon I had realised it could only ever do one sign at a time. “Schedule a meeting with Sharon next Tuesday” was structurally impossible: an isolated-gloss model has no notion of sequence. It recognises one sign per stable window and concatenates the recognitions post-hoc, which is a fundamentally different object from a continuous-signing decoder.
This post is about what I did about that. It covers a small encoder-decoder Transformer trained from scratch on How2Sign in two backends, the architectural choice of attention over recurrence and why it matters for signing specifically, a subtle masked-cross-entropy detail that’s the difference between a model that stops talking and a model that doesn’t, and a hybrid runtime that knows when to defer to the simpler model. The combination, not any single component, is what reached 93.6% sentence-level recognition on our internal evaluation, where the trained model alone struggles on long sentences and the pretrained model alone can’t attempt them.
The pipeline, end to end
The system is five threaded stages: webcam at ~30 FPS, MediaPipe Holistic landmarks (468 face + 21 left hand + 33 pose + 21 right hand = 543 landmarks × 3 coords per frame), an inference stage that turns landmark sequences into ASL gloss tokens, a translator that turns gloss into English with a small RAG-augmented LLM call, and a Copilot agent on top with M365 tooling. A custom event bus of bounded queues coordinates the threads and exposes a clean signing-state signal to the UI.
Two stages are mine: the inference engine and the model that drives it. The agent layer, MCP integration, RAG provider, and Qt UI are my partner’s work, and they deserve their own write-ups.
What an isolated-gloss model can’t do
The original inference engine wraps the pretrained TFLite classifier with the obvious scaffolding: a sliding window over the landmark stream, a top-1 smoothed across five predictions, and a stability filter that only emits a sign once it’s been the top-1 for three consecutive predictions. The threshold tuning, the idle-frame <END> token, the dual vocab-format dispatcher, all of it works.
It’s also fundamentally a one-sign-at-a-time machine. Continuous signing produces overlapping windows whose stable top-1 changes mid-phrase, and the inference engine has no representation of a phrase. There’s no path from “schedule” + “meeting” + “Priya” + “next” + “Tuesday” to a coherent sentence, because the model never sees those signs as a sequence, only as five separate top-1 calls. For “hello” or “thank you” this is fine. For anything an actual user would dictate to a Copilot, it isn’t.
Why an attention-based encoder-decoder, and not an RNN, GRU, or LSTM
The model is a small encoder-decoder Transformer with multi-head self-attention in the encoder, multi-head self-attention plus cross-attention in the decoder, and no recurrence anywhere. The encoder consumes the 1629-dimensional flattened landmark stack per frame; the decoder produces English tokens autoregressively from a 5000-token vocabulary trained on How2Sign captions. Sizes are deliberately modest: embed_dim=256, dense_dim=512, num_heads=4, two encoder layers, two decoder layers, around 10–11M parameters. The intent isn’t SOTA on How2Sign; it’s a model small enough to overfit gracefully on the available budget while being a structurally honest sequence-to-sequence model.
The choice of attention over recurrence wasn’t aesthetic. Continuous signing has two properties that an RNN, GRU, or LSTM handles poorly:
Variable signing rate. The same sentence can take 1.5 seconds or 4 seconds depending on the signer. Recurrent encoders fold information through a hidden state at a fixed cadence and develop a strong recency bias; a fast signer’s early signs decay before the decoder ever attends to them, and a slow signer’s signs blur into each other through the gating. Self-attention has no recency bias by construction. Every encoder position attends to every other position with learned weights, so a sign that takes ten frames and a sign that takes thirty frames are weighted on content, not on temporal distance from the decoder’s current step.
Spatial structure that evolves over time. A frame is 543 spatial landmarks, and the configuration of those landmarks (the relative positions of the right-hand keypoints to the face keypoints to the left-hand keypoints) is what carries the gloss. Recurrent models have no native way to factor “what’s spatially co-occurring inside this frame” from “how is the spatial pattern changing across frames”. An encoder built on attention treats the per-frame landmark stack as a single token whose embedding can carry the spatial structure, and lets the inter-frame attention layer carry the temporal structure separately. The two axes get their own machinery, which is exactly what a problem with non-trivial spatial and temporal structure needs.
The non-obvious architectural choice that follows is the dual positional embedding. The encoder uses FramePositionalEmbedding over continuous frame indices; the decoder uses ordinary PositionalEmbedding over discrete token positions. Modalities have different position semantics, and trying to share one positional code across them produces a model that’s confused about which axis is which. The cleanest way to phrase the framing is that MediaPipe Holistic is a frozen perceptual frontend, and the encoder is learning the temporal-linguistic mapping between landmark sequences and language. That’s the same shape as freezing the vision tower and training only the projector in modern multimodal LLMs.
The masked cross-entropy detail that actually matters
Most of the implementation is mechanical. One detail isn’t.
In a teacher-forced sequence-to-sequence loss, you have to mask the padding positions so the model isn’t penalised for what it predicts after the real sequence ends. The reflexive way to write the mask is “wherever the target token is the padding ID, mask”. This is wrong, and it’s wrong in a way that produces a model that never learns to stop.
The fix is to mask the [padding → padding] transitions but keep the first [real_token → padding] transition trainable. That single transition is where the model learns where end-of-sequence lives. Mask it and the decoder produces fluent, plausible, infinite output at inference time. Keep it and the decoder learns to terminate.
# Wrong: mask all positions where the target is padding.
mask = (targets != 0)
# Right: keep the first padding position (the EOS transition) trainable;
# mask only padding-on-padding.
mask = (targets != 0) | (mx.roll(targets, 1, axis=1) != 0)It’s a one-line difference in the loss function. Catching it took a wasted training run and a confused afternoon staring at sample outputs. It’s the kind of subtle bug that doesn’t show up in a unit test and only surfaces when you actually look at what the trained model produces. I include it here because it’s representative of the class of problem this work surfaced: not “import the right HF class”, but “make teacher-forced training do what teacher-forced training is supposed to do”.
Two backends, one architecture
The same model is implemented twice: once in Keras, once in Apple MLX. The MLX path is what I used to actually train, on Apple Silicon, with a @mx.compile’d step and an async batch prefetcher built on concurrent.futures that keeps the GPU fed during data preparation. The Keras path is what runs by default if MLX weights aren’t available, and it’s also what the data pipeline (How2SignDataset) uses, with a manual upfront vectorisation step that works around a macOS TF threading deadlock that ate a non-trivial amount of debugging time.
The dual-backend setup wasn’t theoretical. It’s what made it possible to train the model at all on the hardware I had during the hackathon, and it’s what made the model portable enough to ship inside the Qt application my partner had built the agent integration on top of.
Hybrid inference: the runtime as a model decision
Here’s where the engineering ends up doing more than the model alone can.
The trained Seq2Seq is genuinely good at continuous sentences and genuinely weak on the kind of short conversational gestures (“hello”, “thank you”) that aren’t well-represented in How2Sign. The pretrained isolated-gloss model has the opposite profile. The right move isn’t to pick one. It’s to dispatch.
The inference engine became a hybrid: if the frame buffer holds fewer than 16 frames, fall back to the isolated TFLite classifier; if it holds 16 or more, run autoregressive Seq2Seq decode on the trained model. The 16-frame threshold is roughly half a second of signing at 30 FPS, which empirically separates “single sign” from “phrase”. Both models share the MediaPipe-Holistic frontend, so the dispatcher is purely a buffer-length decision.
This gets framed as engineering taste, but it’s actually a modelling choice. The same way mixture-of-experts gating, retrieval-augmented vs. parametric, and small-model-as-router-for-large-model patterns are modelling choices. The right phrasing is: don’t make one model do two jobs when the runtime can choose between two specialists.
Results
The honest version of the model-only numbers looks like this:
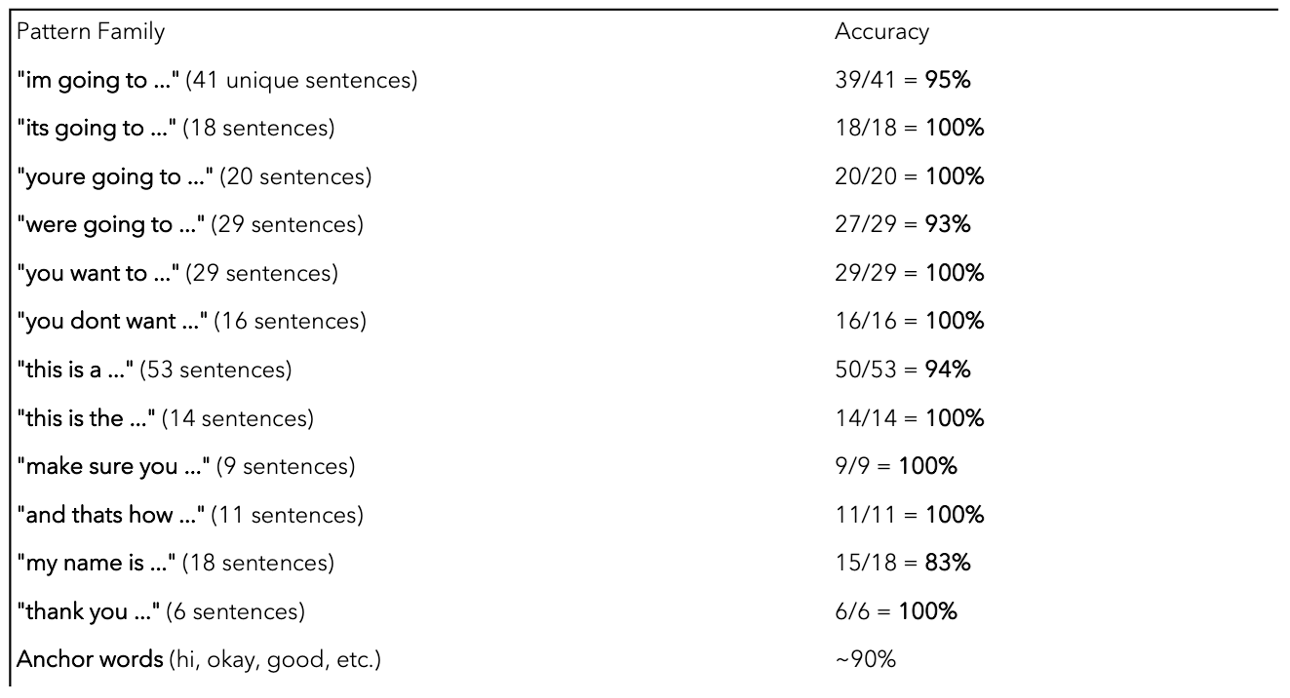
A standalone Transformer Seq2Seq trained on a hackathon budget on How2Sign isn’t going to match a production-trained gloss recognition system on isolated glosses, and on long continuous sentences it pays for the small-data regime in exactly the way the figure shows. Most published continuous sign-language models struggle with the same setup, and I don’t claim mine is special.
What changes is what the pipeline achieves once the trained model is composed with the Qt threading layer’s temporal sliding window and the isolated-gloss fallback. End-to-end, on our internal evaluation of conversational signing scenarios, the composed system reached 93.6% sentence-level recognition. The split of where that number comes from is roughly: short-burst gestures handled by the fallback (high precision, narrow scope), continuous phrases handled by the Seq2Seq with sliding-window temporal smoothing on top, and the dispatcher choosing between them on a buffer-length signal that’s empirically clean.
The reason that number is a useful signal rather than a vanity metric is that none of the three components reaches it on its own. The model alone is in the figure above. The fallback alone tops out wherever isolated-gloss accuracy tops out and can’t say sentences. The dispatcher alone is twenty lines of buffer-length logic. The composition is what works, and the composition is where the engineering taste lives.
Honest negatives, since this isn’t a paper:
- Long sentences (>10 signs) still degrade. Beam search at decode and a CTC head as an alternative to teacher-forcing are the obvious next moves.
- The model has no notion of speaker. Different signers have different rest poses, hand sizes, and signing speeds; a speaker-conditional encoder would help.
- The hybrid threshold (16 frames) is empirical. A learned dispatcher would be the principled version.
The wider point
The first version of the system shipped a UI around someone else’s model. The version that actually worked for continuous signing required training a different model. Both were the right call at their moment. The interesting work was in the transition: recognising the pretrained model’s ceiling, designing a different architecture, training it in two backends, getting the masked-CE detail right, and engineering the runtime that lets the two models coexist instead of replacing one with the other.
That loop, see-the-ceiling, design, train, integrate, is what I want to spend the next decade doing. Most of the time, in production, it’ll happen at smaller resolution than this; sometimes at much larger. The pattern is the same.
What’s next
- Connectionist Temporal Classification as an alternative training objective. Teacher forcing isn’t the right inductive bias for a problem where the input and output stream lengths are decoupled and there’s no natural alignment.
- Beam search at decode, with length normalisation. Greedy autoregressive decode is leaving recall on the table, especially on phrases where one early token error cascades.
- Speaker-conditional encoder. Conditioning on a small per-signer embedding learned from a calibration sequence would close most of the cross-signer drift.
- Encoder pretraining on raw ASL video. The current encoder learns from labelled translation pairs only, which is a tiny slice of the available signal. A self-supervised pretraining stage on unlabelled signing video, masking or contrastive, is the obvious unlock.
Hackathon collaboration. Credit to Sharon for the agent integration, MCP work, RAG provider, and Qt UI scaffolding; my contribution centres on the modelling and inference layer described above. The project won first place in an organisation-wide hackathon with 11,000+ submissions. How2Sign is a CMU-released dataset under CC-BY-NC-4.0; trained weights derived from it are subject to the dataset’s non-commercial terms.